How to T Test Non Continuous Data
Problem Statement
In our sample dataset, students reported their typical time to run a mile, and whether or not they were an athlete. Suppose we want to know if the average time to run a mile is different for athletes versus non-athletes. This involves testing whether the sample means for mile time among athletes and non-athletes in your sample are statistically different (and by extension, inferring whether the means for mile times in the population are significantly different between these two groups). You can use an Independent Samples t Test to compare the mean mile time for athletes and non-athletes.
The hypotheses for this example can be expressed as:
H 0: µnon-athlete − µathlete = 0 ("the difference of the means is equal to zero")
H 1: µnon-athlete − µathlete ≠ 0 ("the difference of the means is not equal to zero")
where µathlete and µnon-athlete are the population means for athletes and non-athletes, respectively.
In the sample data, we will use two variables: Athlete and MileMinDur. The variable Athlete has values of either "0" (non-athlete) or "1" (athlete). It will function as the independent variable in this T test. The variable MileMinDur is a numeric duration variable (h:mm:ss), and it will function as the dependent variable. In SPSS, the first few rows of data look like this:
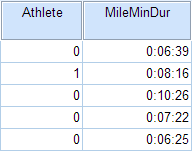
Before the Test
Before running the Independent Samples t Test, it is a good idea to look at descriptive statistics and graphs to get an idea of what to expect. Running Compare Means (Analyze > Compare Means > Means) to get descriptive statistics by group tells us that the standard deviation in mile time for non-athletes is about 2 minutes; for athletes, it is about 49 seconds. This corresponds to a variance of 14803 seconds for non-athletes, and a variance of 2447 seconds for athletes1. Running the Explore procedure (Analyze > Descriptives > Explore) to obtain a comparative boxplot yields the following graph:
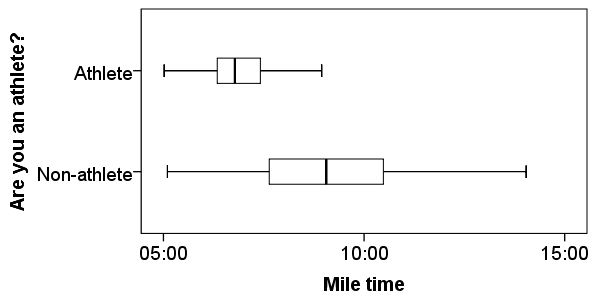
If the variances were indeed equal, we would expect the total length of the boxplots to be about the same for both groups. However, from this boxplot, it is clear that the spread of observations for non-athletes is much greater than the spread of observations for athletes. Already, we can estimate that the variances for these two groups are quite different. It should not come as a surprise if we run the Independent Samples t Test and see that Levene's Test is significant.
Additionally, we should also decide on a significance level (typically denoted using the Greek letter alpha, α) before we perform our hypothesis tests. The significance level is the threshold we use to decide whether a test result is significant. For this example, let's use α = 0.05.
1When computing the variance of a duration variable (formatted as hh:mm:ss or mm:ss or mm:ss.s), SPSS converts the standard deviation value to seconds before squaring.
Running the Test
To run the Independent Samples t Test:
- ClickAnalyze > Compare Means > Independent-Samples T Test.
- Move the variable Athlete to the Grouping Variable field, and move the variable MileMinDur to the Test Variable(s) area. Now Athlete is defined as the independent variable and MileMinDur is defined as the dependent variable.
- Click Define Groups, which opens a new window. Use specified values is selected by default. Since our grouping variable is numerically coded (0 = "Non-athlete", 1 = "Athlete"), type "0" in the first text box, and "1" in the second text box. This indicates that we will compare groups 0 and 1, which correspond to non-athletes and athletes, respectively. Click Continue when finished.
- Click OK to run the Independent Samples t Test. Output for the analysis will display in the Output Viewer window.
Syntax
T-TEST GROUPS=Athlete(0 1) /MISSING=ANALYSIS /VARIABLES=MileMinDur /CRITERIA=CI(.95). Output
Tables
Two sections (boxes) appear in the output: Group Statistics and Independent Samples Test. The first section, Group Statistics, provides basic information about the group comparisons, including the sample size (n), mean, standard deviation, and standard error for mile times by group. In this example, there are 166 athletes and 226 non-athletes. The mean mile time for athletes is 6 minutes 51 seconds, and the mean mile time for non-athletes is 9 minutes 6 seconds.
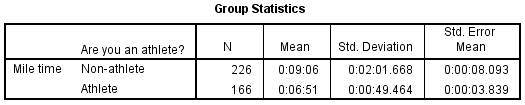
The second section, Independent Samples Test, displays the results most relevant to the Independent Samples t Test. There are two parts that provide different pieces of information: (A) Levene's Test for Equality of Variances and (B) t-test for Equality of Means.
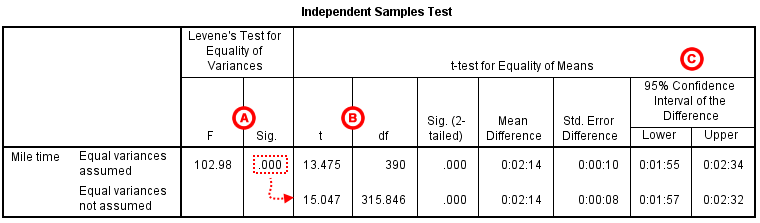
A Levene's Test for Equality of of Variances: This section has the test results for Levene's Test. From left to right:
- F is the test statistic of Levene's test
- Sig. is the p-value corresponding to this test statistic.
The p-value of Levene's test is printed as ".000" (but should be read as p < 0.001 -- i.e., p very small), so we we reject the null of Levene's test and conclude that the variance in mile time of athletes is significantly different than that of non-athletes. This tells us that we should look at the "Equal variances not assumed" row for the t test (and corresponding confidence interval) results. (If this test result had not been significant -- that is, if we had observed p > α -- then we would have used the "Equal variances assumed" output.)
B t-test for Equality of Means provides the results for the actual Independent Samples t Test. From left to right:
- t is the computed test statistic, using the formula for the equal-variances-assumed test statistic (first row of table) or the formula for the equal-variances-not-assumed test statistic (second row of table)
- df is the degrees of freedom, using the equal-variances-assumed degrees of freedom formula (first row of table) or the equal-variances-not-assumed degrees of freedom formula (second row of table)
- Sig (2-tailed) is the p-value corresponding to the given test statistic and degrees of freedom
- Mean Difference is the difference between the sample means, i.e. x 1 − x 2; it also corresponds to the numerator of the test statistic for that test
- Std. Error Difference is the standard error of the mean difference estimate; it also corresponds to the denominator of the test statistic for that test
Note that the mean difference is calculated by subtracting the mean of the second group from the mean of the first group. In this example, the mean mile time for athletes was subtracted from the mean mile time for non-athletes (9:06 minus 6:51 = 02:14). The sign of the mean difference corresponds to the sign of the t value. The positive t value in this example indicates that the mean mile time for the first group, non-athletes, is significantly greater than the mean for the second group, athletes.
The associated p value is printed as ".000"; double-clicking on the p-value will reveal the un-rounded number. SPSS rounds p-values to three decimal places, so any p-value too small to round up to .001 will print as .000. (In this particular example, the p-values are on the order of 10-40.)
C Confidence Interval of the Difference: This part of the t-test output complements the significance test results. Typically, if the CI for the mean difference contains 0 within the interval -- i.e., if the lower boundary of the CI is a negative number and the upper boundary of the CI is a positive number -- the results are not significant at the chosen significance level. In this example, the 95% CI is [01:57, 02:32], which does not contain zero; this agrees with the small p-value of the significance test.
Decision and Conclusions
Since p < .001 is less than our chosen significance level α = 0.05, we can reject the null hypothesis, and conclude that the that the mean mile time for athletes and non-athletes is significantly different.
Based on the results, we can state the following:
- There was a significant difference in mean mile time between non-athletes and athletes (t 315.846 = 15.047, p < .001).
- The average mile time for athletes was 2 minutes and 14 seconds lower than the average mile time for non-athletes.
Source: https://libguides.library.kent.edu/spss/independentttest
0 Response to "How to T Test Non Continuous Data"
Post a Comment